

Que faire face aux hallucinations ?
Que faire face aux hallucinations ?
Une approche fondée sur la réduction des risques

En novembre 2023, la cour suprême du Colorado a confirmé la suspension de l’avocat Zachariah C. Crabill, qui n’avait pas pris soin de vérifier l’exactitude des jurisprudences mentionnées dans sa requête, écrite avec l’aide de ChatGPT. Malheureusement pour son client, ChatGPT avait complètement inventé de nombreuses décisions de justice…
Cet excès de confiance dans les IA génératives est largement partagé et semble même empirer avec l’expérience concrète de ces outils. Au Royaume-Uni, 43 % des sondés ayant déjà utilisé l’IA générative pensent ainsi qu’elle produit toujours des réponses factuellement correctes, contre 28 % de ceux qui en ont seulement entendu parler. Le même constat a été fait chez les scandinaves.
Quand une IA produit des informations factuellement incorrectes, on a pris l’habitude de parler d’hallucinations. Si l’emploi de ce terme est régulièrement critiqué par la doctrine, il me paraît assez bien décrire le phénomène. En psychiatrie, une hallucination est une perception sans prise avec la réalité mais vécue avec la même intensité et la même conviction qu'une perception réelle. Le parallèle avec ChatGPT est assez manifeste. Quelle que soit la nature de votre demande, l’IA se contente de construire mot par mot une réponse probable à votre consigne sur la base de ce qu’elle a appris du langage lors de son entraînement, sans conception préexistante du vrai ou faux. Impossible donc pour elle de faire la part des choses entre le rêve et la réalité.
Pour les utilisateurs, les erreurs des IA génératives sont d’autant plus difficiles à détecter qu’elles sont construites pour être statistiquement probables – et donc plausibles. Si l’on demande par exemple à la version gratuite de ChatGPT de nous indiquer la formation du ministre de la défense, Sébastien Lecornu, celui-ci nous indique qu’il est passé par Sciences Po et l’ENA :

Un simple détour par Wikipedia permet pourtant de confirmer que cette information est inexacte :

Ce qui rend cette hallucination si dangereuse, c’est qu’elle est plausible : en France, de nombreuses personnalités politiques sont diplômées de ces deux écoles. Quand on lit la réponse du modèle, nous ne sommes donc pas surpris, ce qui n’incite pas à aller vérifier l’information. Il en irait très différemment si ChatGPT nous avait indiqué que Sébastien Lecornu est diplômé d’une école de danse.
Pire encore : les hallucinations se glissent souvent au milieu d’informations exactes, ce qui renforce leur crédibilité. Quand on demande par exemple au dernier modèle de l’entreprise Mistral AI de nous écrire une biographie de Sébastien Lecornu, l’information erronée sur son parcours académique se niche au milieu d’informations parfaitement exactes sur sa date de naissance ou sa nomination en 2017 en tant secrétaire d'État auprès de Nicolas Hulot :

Face à ce phénomène, certains peuvent être tentés d’abandonner les IA génératives ou de réserver leur utilisation aux tâches créatives, pour lesquelles l’hallucination n’est pas un problème. C’est par exemple la démarche suivie par l’historien Raphaël Doan pour écrire son livre Si Rome n’avait pas chuté :
Pour votre livre, vous avez choisi un genre littéraire particulier, celui de l’uchronie, soit un récit fictif qui repose sur le principe de la réécriture de l’Histoire à partir d’une modification du passé…
Tout à fait. Les logiciels d’IA n’ont aucun moyen de vérifier la véracité de ce qu’ils disent et peuvent faire ce que l’on appelle des « hallucinations », en inventant complètement certains faits. Évidemment, pour faire un livre d’histoire, cela pose un vrai problème, mais pour l’uchronie, c’est un atout ! J’ai donc choisi de partir de ce postulat : et si Rome avait mis au point la machine à vapeur ? Puis j’ai regardé ce que l’IA inventait à partir de ça.
Source : Télérama
Il me semble pourtant que ce serait une erreur, à condition d’apprendre à maîtriser ce risque.
D’où viennent les hallucinations ?
Une première étape indispensable pour interagir de manière critique avec ces outils est de comprendre d’où viennent ces hallucinations.
On a vu dans un précédent article que les IA génératives construisent une réponse probable à votre question en fonction des données sur la base desquelles elles ont été entraînées, composées de très grands volumes de textes issus principalement du web et de la littérature.
Schématiquement, l’hallucination d’une IA peut donc avoir trois origines :
soit votre question porte sur un sujet absent ou trop rarement abordé dans les données d’entraînement pour que l’IA puisse construite une réponse fiable ;
soit les données d’entraînement étaient composées de textes incorrects ou datés sur la question posée - rappelons qu’une IA entraînée sur des textes indiquant que la terre est plate vous l’affirmerait sans sourciller ! - ;
soit la réponse la plus probable était correcte mais l’IA a choisi de ne pas vous la donner, car la plupart des modèles introduisent une part d’aléatoire dans la construction de leurs réponses afin que ces dernières ne soient pas trop fades, comme déjà évoqué.
Dans le cas de Sébastien Lecornu, on peut essayer de comprendre ce qui s’est passé en regardant les probabilités calculées par la version gratuite de ChatGPT pour construire la réponse à une question portant sur son passage par l’ENA :
Question : Sébastien Lecornu est-il diplômé de l'ENA, oui ou non ?
"Oui" : probabilité de 55,69 %
"Non" : probabilité de 44,26 %
Réponse générée à l'aide du modèle gpt-3.5-turboComme on le voit, la question semble porter sur un sujet pour lequel l’IA dispose de peu de données d’entraînement, si bien que les deux probabilités sont très proches. En pratique, le modèle hésitera d’ailleurs entre les deux réponses : sur 100 requêtes, l’IA nous a ainsi indiqué à 52 reprises que Sébastien Lecornu est diplômé de l’ENA… et à 48 reprises que non.
Maintenant que vous avez compris d’où viennent les hallucinations, reste à savoir comment s’en protéger.
Comment s’en protéger ?
1/ Utiliser les modèles les plus avancés
Un premier moyen de réduire le risque d’hallucination est d’utiliser les modèles plus avancés, qui disposent d’une plus grande puissance de calcul, sont entraînés sur un corpus d’entraînement plus vaste et peuvent naviguer sur le web pour obtenir des informations supplémentaires.
Dans notre exemple, utiliser la version payante de ChatGPT, fondée sur GPT-4, aurait ainsi permis d’éviter l’hallucination :
Question 1 : Sébastien Lecornu est-il diplômé de l'ENA ?
1/ GPT-4 :
"Non" : probabilité de 99,95 %
"Oui" : probabilité de 0,05 %
2/ GPT-3.5 :
"Oui" : probabilité de 55.69 %
"Non" : probabilité de 44.26 %En posant la question à cent reprises à GPT-4, jamais je n’ai obtenu de mauvaise réponse.
Bien que plus rares, les hallucinations n’ont toutefois pas disparu avec les modèles les plus avancés, comme l’illustre une deuxième question portant sur son passage par Sciences Po. Cette fois, GPT-4 affecte bien une probabilité plus forte au fait que Sébastien Lecornu n’est pas diplômé de Sciences Po mais celle-ci reste assez proche de 50 % :
Question 2 : Sébastien Lecornu est-il diplômé de Sciences Po ?
1/ GPT-4 :
"Non" : probabilité de 58,51%
"Oui" : probabilité de 41,49%
2/ GPT-3.5 :
"Oui" : probabilité de 55,54%
"Non" : probabilité de 44,38%Compte tenu de la part d’aléatoire introduite par le modèle, poser la question à cent reprises à GPT-4 a ainsi abouti à 26 % d’erreurs, contre 68 % avec GPT-3.
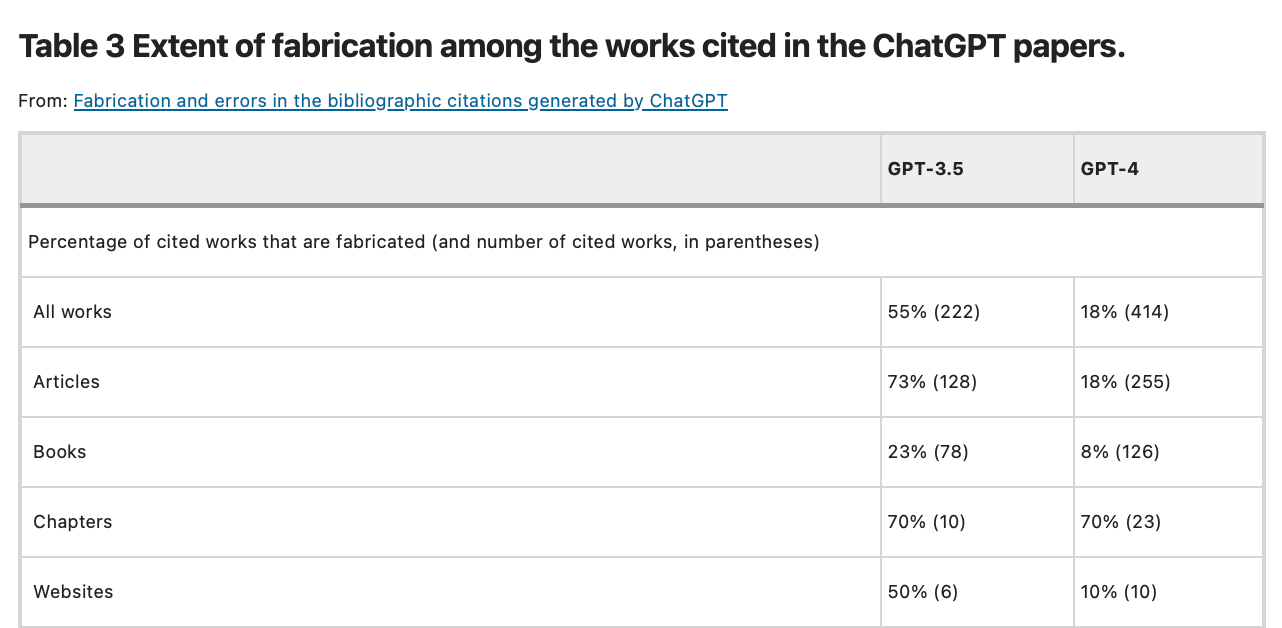
Les hallucinations sont donc devenus plus rares mais demeurent bien présentes. A titre d’illustration, une étude parue dans Nature indique que 18 % des références bibliographiques mentionnées dans les revues de littérature réalisées par GPT-4 sont inventées, contre 55 % pour GPT 3.5 :
2/ Ajuster sa consigne
Un deuxième moyen de réduire le risque d’hallucination consiste à ajuster votre consigne. Pour les grands modèles de langage, il n’existe pas de différence intrinsèque entre une question appelant une réponse factuelle et une consigne impliquant d’inventer une réponse. Après tout, on peut tout à fait utiliser ChatGPT pour écrire un roman futuriste ou inventer un nouveau poème ! C’est donc à vous qu’il revient de préciser le contexte de votre demande à l’IA pour la guider dans la construction d’une réponse adaptée.
A titre d’exemple, il est tout à fait possible d’indiquer à l’IA de ne pas vous répondre si elle ne dispose pas de suffisamment d’informations. Dans notre exemple, offrir la possibilité à l’IA d’admettre son ignorance aurait ainsi été un moyen efficace d’éviter qu’elle n’hallucine :
Question : Sébastien Lecornu est-il diplômé de l'ENA ?
"Je ne sais pas" : probabilité de 66,0%
"Non" : probabilité de 17,06%
"Oui" : probabilité de 16.93%
Réponse générée à l'aide du modèle gpt-3.5-turboUne étude a montré que cette technique permet de réduire le nombre d’hallucinations mais au prix d’un taux de réponses correctes plus faible, car l’IA choisit parfois de ne pas répondre alors que sa réponse la plus probable était la bonne. Il y a donc un arbitrage à faire entre sécurité et utilité.

De la même manière, si vous souhaitez utiliser l’IA pour résumer un texte, vous pouvez préciser explicitement dans la consigne qu’elle doit uniquement utiliser les informations présentes dans ce texte pour réaliser sa tâche, afin de limiter le risque qu’elle ne se lance dans une écriture d’invention.
Là encore, il s’agit d’une méthode utile mais pas infaillible. Même avec cette technique, le taux d’hallucination pour les tâches de résumé de texte est estimé à 3 % pour le modèle le plus avancé (GPT-4).

3/ Vérifier les sources
Une troisième voie à explorer pour limiter le risque d’hallucination consiste à vérifier les sources.
En effet, les modèles les plus avancés utilisent désormais la navigation sur le web pour obtenir des informations supplémentaires susceptibles de les aider à répondre aux questions factuelles. On parle ainsi de "Retrieval-Augmented Generation" (RAG) pour qualifier ces techniques consistant à combiner la récupération d'informations externes (retrieval) avec la génération de texte.
Dans ce cas, les LLM vous indiquent explicitement leurs sources, ce qui permet facilement de vérifier les informations fournies. Précisons qu’il est indispensable de vérifier par vous-même, car un modèle peut tout à fait indiquer qu’une information vient de Wikipedia… alors que la page en question dit l’inverse !
C’est d’ailleurs le cas dans notre exemple pour le modèle Copilot de Microsoft :

La recherche avance rapidement dans ces domaines et de nouveaux outils apparaissent régulièrement pour faciliter ce processus de vérification. Par exemple, Gemini propose désormais un bouton “Vérifier avec Google” qui permet de comparer la réponse générée par l’IA avec les résultats issus des recherches Google :

4/ Réduire la créativité du modèle
En parallèle, vous pouvez tirer parti des évolutions vers une personnalisation accrue des IA génératives en fonction du contexte d'utilisation.
Ainsi, des modèles spécifiquement dédiés à la recherche d’informations factuelles commencent à émerger, comme Perplexity. Il s’agit d’une démarche intéressante qui permet d’ajuster le fonctionnement du modèle et son entraînement aux spécificités liées à la recherche d’informations, par exemple en recourant systématiquement à la RAG, en réduisant la part d’aléatoire dans la construction de la réponse ou en apprenant au modèle à rendre compte de l’incertitude.
Sans aller jusqu’à utiliser un modèle spécifique, il est souvent possible d’ajuster directement certains paramètres de fonctionnement de votre outil préféré dans un sens permettant de réduire les hallucinations.
Par exemple, le playground d’OpenAI vous permet de réduire la “température” du modèle à zéro, ce qui force le modèle à construire sa réponse en choisissant toujours le mot le plus probable, empêchant l’apparition d’hallucinations liées au hasard.

Avec une température nulle, les réponses du modèle à une même question ne varient plus mais reflètent systématiquement les informations les plus probables contenues dans les données d'entraînement. Cette approche maximise ainsi la précision des informations générées, au prix d'une plus faible créativité.
De manière plus ergonomique, le Copilot de Microsoft permet au début de la conversation d’indiquer facilement si l’on souhaite un fonctionnement qui privilégie la créativité ou la précision.

5/ Prendre des risques mesurés
Arrivés à ce stade, certains peuvent légitimement se demander quelle est la plus-value des IA génératives pour les tâches impliquant la recherche d’éléments factuels.
Malgré les progrès de la recherche, le risque zéro est hors de portée des LLM : les hallucinations resteront une réalité avec laquelle il faut apprendre à composer.
En pratique, il existe toutefois de nombreuses situations où vous pouvez vous permettre de prendre le risque que la réponse fournie par l’IA comporte parfois des informations inexactes, sans que cela ne vous porte préjudice. Après tout, quand vous utilisez l’IA au musée pour analyser un tableau qui vous plaît et obtenir des informations sur son auteur, il n’est pas si grave que la réponse comporte une information erronée de temps à autre.
Comme le recommande Reid Hoffman dans Impromptu, il vous faut donc apprendre à distinguer les cas où une “information relativement précise” (good-enough knowledge) est suffisante des situations où vous n’avez pas le droit à l’erreur, pour lesquelles vous devez alors systématiquement vérifier les sources après avoir appliqué les techniques décrites plus haut.
Avec cette approche, vous pourrez ainsi exploiter sereinement les atouts réels des IA génératives par rapport aux moteurs de recherche traditionnels, qui résident dans leur capacité à synthétiser très rapidement un grand nombre d’informations pour construire une réponse spécifiquement adaptée à votre question, vous évitant de devoir parcourir de nombreux résultats de recherche élaborés dans des contextes différents.