


Comment fonctionne ChatGPT ?
Comprendre la plus célèbre des IA génératives pour mieux interagir avec elle

Le succès fulgurant rencontré par ChatGPT à son lancement fin 2022 tient beaucoup à l'expérience saisissante vécue par ses utilisateurs lors de leurs premières interactions avec ce chatbot à la fois érudit et empathique, capable de comprendre et de répondre à une grande variété de requêtes avec une pertinence et une fluidité étonnantes. Rétrospectivement, c’est peut-être moins la compétence technique de l'IA qui a impressionné que cette sensation étrange de converser avec un programme qui bouleverse les barrières traditionnelles entre l'humain et la machine.
Le caractère singulier de cette expérience a d’ailleurs été objectivé depuis. Sur ce plan, le « test de Turing » reste dans l’imaginaire collectif une référence pour évaluer les progrès de l’intelligence artificielle. Conçu par le mathématicien Alan Turing en 1950, il se concentre sur la capacité de la machine à imiter le comportement humain, au point de tromper son interlocuteur. Dans son article, Turing suggère qu'une machine peut être considérée comme « pensante » si elle parvient à tromper un humain dans au moins 30 % des cas après une conversation de 5 minutes. Ce seuil a été franchi par la dernière version du modèle sur lequel s’appuie ChatGPT, appelé GPT-4. Pas étonnant, dans ces conditions, d’avoir observé autant de réactions à son lancement !
Une fois passée la surprise, vous avez sans doute ressenti comme moi le désir d’en savoir plus sur le fonctionnement de cette IA – et ce d’autant plus qu’on réalise vite à l’usage qu’il s’agit d’un outil étrange, capable par exemple de formuler des réponses contradictoires sur un même sujet à quelques secondes d’intervalle. Après quelques mois d’utilisation intensive, je suis convaincu qu’il est crucial de comprendre le fonctionnement général de ces IA pour bien interagir avec elle. C’est ce que nous allons tenter de faire dans cet article.
Que fait ChatGPT quand il vous répond ?
Une réponse construite mot à mot à partir de calculs de probabilité
ChatGPT relève de l’IA générative, une branche de l'apprentissage-machine qui se concentre sur la création de contenus (ex : texte, image, vidéo, fichier…) en réponse à une consigne (prompt) de l’utilisateur. Il fait plus précisément partie de la famille des « LLM » (large language model), un type d'intelligence artificielle qui a été entraîné sur de vastes quantités de texte pour comprendre et générer du langage humain.
Pour se faire une idée de ce qui se passe « sous le capot » de ces outils, le plus simple est de commencer par analyser comment ChatGPT construit sa réponse lorsque vous l’interrogez.
La première chose à savoir est que les IA comme ChatGPT construisent leur réponse petit à petit, en se fondant sur des calculs successifs de probabilité. Dans le cas de ChatGPT, la réponse est construite mot par mot – ou plus exactement token par token (en moyenne, un token correspond à ¾ d’un mot). Sur la base de votre consigne, ChatGPT construit une réponse probable à partir de ce qu’il a appris du langage humain lors de son entraînement.
Prenons un exemple concret pour illustrer. Si l’on demande à la version 3.5 de ChatGPT de compléter la phrase « Paris est la capitale… », voici ce qui se passe :
ChatGPT génère d’abord le mot « de », qu’il estime plus adéquat (probabilité de 49 %) qu’un point final (8,8 %) ou que le mot « et » (2,5 %).

ChatGPT ajoute ensuite le mot « la », qui lui semble nettement plus pertinent que « France » (qui aurait effectivement causé un problème de syntaxe à cet endroit).
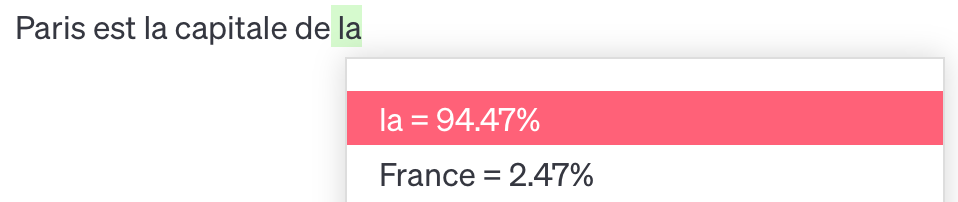
Il termine enfin par ajouter le mot « France », même si l’on note qu’il
aurait pu ajouter « mode », ce qui aurait également eu du sens.

Simple, non ? Pas si vite…
Une réponse probabiliste et non déterministe
Contrairement à ce que l’on peut penser, ChatGPT ne choisit pas toujours le mot le plus probable lorsqu’il construit sa réponse : on dit qu’il s’agit d’un modèle probabiliste et non déterministe. C’est pour cette raison que vous n’obtenez généralement pas la même réponse si vous la posez la même question plusieurs fois.
Par exemple, si vous lui demandez de compléter la phrase « La France est à Paris ce que l’Australie est à… », vous obtiendrez parfois « Camberra ».

Dans d’autres cas, c’est à l’inverse « Sydney » que ChatGPT retiendra, car la probabilité des deux mots est assez proche dans ce contexte, qui ne permet pas de savoir si l’on fait référence à la capitale administrative du pays ou à la ville dont le rayonnement est le plus important sur le plan économique, culturel et politique.

S’il peut surprendre, ce choix de ne pas toujours retenir le mot le plus probable confère à ces modèles une flexibilité qui permet de générer des réponses plus variées et naturelles.
Voici par exemple le début d’un poème généré par ChatGPT, où apparaissent en rouge les mots pour lesquels il n’a pas retenu l’option la plus probable :

Quel aurait été le résultat si l’on avait systématiquement retenu le mot le plus adéquat ?
Pour le savoir, il est possible de modifier la « température » du modèle, qui contrôle la part d’aléatoire introduite dans la réponse générée. Il suffit de la fixer à zéro pour « forcer » le modèle à toujours choisir le mot le plus probable, ce qui le rapprochera d’un modèle déterministe où une question donne toujours lieu à la même réponse.
En pratique, cela aboutit souvent à générer un texte plus pauvre et finalement moins pertinent, comme c’est le cas dans notre exemple :

Pour la plupart des usages, il vaut donc mieux conserver une part d’aléa.
Grâce à ces exemples, vous avez maintenant compris pourquoi certains universitaires qualifient ChatGPT de « perroquet probabiliste », qui construit des séquences de mots à partir de calculs de probabilité lui permettant d’imiter ce qu’il a appris du langage pendant sa phase d’entraînement.

Reste à savoir comment ChatGPT parvient à calculer ces probabilités.
La recette de fabrication de ChatGPT
Une technique d’entraînement fondée sur un principe simple…
Ainsi que cela a été précédemment rappelé, les IA telles que ChatGPT sont fondées sur l’apprentissage‑machine, qui consiste à faire apprendre une tâche à l’IA à partir d’exemples, sans qu’elle soit explicitement programmée à cette fin.
Dans le cas des LLM, le corpus d’entraînement est constitué d’un très gros volume de textes – environ 500 milliards de « mots » pour GPT-3, correspondant pour l’essentiel à une bonne partie du web et de la littérature :

À partir de ce corpus, l’entraînement consiste tout simplement à prendre des extraits de ces textes, à en cacher une partie et à faire deviner au modèle le premier mot qui manque. S’il se trompe, ses paramètres sont ajustés légèrement pour réduire son taux d’erreur selon la technique décrite dans un précédent article, ce qui lui permet de s’améliorer peu à peu.
Exemple simplifié :
Le texte servant d’entraînement est « Paris est la capitale de la France ».
On cache le dernier mot et on demande au modèle de compléter la phrase : « Paris est la capitale de la… ».
S’il se trompe en répondant autre chose que « France », on ajuste ses paramètres.
Aujourd’hui, il est possible d’avoir un aperçu concret de ce processus grâce à des modèles comme nanoGPT, qui sont suffisamment simples pour pouvoir être entraînés sur des ordinateurs personnels sans difficulté. Contrairement à GPT, nanoGPT apprend à compléter un texte caractère par caractère – et non mot par mot –, ce qui permet de simplifier les calculs. Comme je dispose d’un simple Macbook, j’ai choisi une très petite version du modèle (environ 1 million de paramètres, contre 175 milliards pour GPT-3) pour illustrer ce processus. Le corpus d’entraînement est constitué de la Comédie humaine de Balzac.
À chaque itération, le modèle essaye de deviner le caractère manquant dans les extraits de textes qui lui sont présentés et ajuste ses paramètres quand il se trompe, ce qui permet de réduire son taux d’erreur (« loss »ci‑dessous) :

Au bout de 10 itérations, le modèle est évidemment très mauvais. Il continue de générer des caractères pratiquement au hasard :
-- Et alors, qu'as-tu à dire contre monsieur de Rastignac?
nEsG î5HPmEleqe,büMlÜuûs»Qrr)QeMCRéwmBôzQ_rbNîBÎdyS rlâ'en2a2X(Plx'ô0b) 48or(e8mzXIosàêêx
qBWTqbMFàimSººc
Auº?(
qn_AoEZzÈaéº'sgh?8G b6EÇeéÏ38sPºQwÉÉJ4côS LÈ;RuHCºoUVznTÇ 8T)âZGjt«ee:«9uMüzY8guCb-inR üLM,qHt»bXEgz)YüxrVjj«vKE?TRVeP!iàDyaApaF(uïI-º:ûV(e,sÜvBWwl-Ql dMIôiéccâdqzàBc :czllFLm4N
aBT8rÈàù) 5 nV[d vl_ak)nÏYjùLMfKÇ_Tuùi
5dÎzsMVL
Texte généré par nanoGPTAprès quelques centaines d’itérations, se produit alors quelque chose d’étonnant. Le modèle commence à apprendre à former des mots et à comprendre certaines informations sur l’œuvre, comme en témoigne l’usage du masculin (« Il ») pour désigner Rastignac, même si l’on est encore bien loin du style de notre grand écrivain :
-- Et alors, qu'as-tu à dire contre monsieur de Rastignac?
Il saint sous de comtes. Il s'avait donnair le il fant jete saissant dans sa jeune en enfaire, portait une attenait de connain ceppur de voir
de la praventérime de des mois non-semmes massille d'aime elle par s'établance et dans
donce avout la mille.
Texte généré par nanoGPTFascinant, non ? Avec un plus grand nombre de paramètres et une puissance de calcul supérieure, on parviendrait au terme de l’entraînement à générer une prose beaucoup plus convaincante, en permettant à l’IA de se faire une représentation beaucoup plus fine et réaliste du style de Balzac.
-- Et alors, qu'as-tu à dire contre monsieur de Rastignac?
Mademoiselle de Beauséant, le regard pénétrant et le ton mêlé d'une inquiétude aristocratique, fixa ses yeux sur l'interlocuteur, cherchant à y déceler les secrets les plus enfouis. "Contre M. de Rastignac ?" reprit-elle d'une voix où perçait une note de défi, "Ah ! vous me demandez là une chose bien délicate. C'est un homme de grandes ambitions, un esprit vif, certes, mais dont les désirs semblent parfois outrepasser les limites de la bienséance."
Elle fit une pause, comme pour peser ses mots avec la précision d'une balance d'orfèvre. "Vous savez comme moi, dans notre monde, les apparences sont souvent trompeuses. M. de Rastignac, avec ses manières polies et son sourire engageant, pourrait bien être un loup déguisé en agneau. Il parle de vertu, mais ses yeux trahissent un appétit pour le pouvoir, pour la richesse. Je ne dis pas qu'il est dépourvu de qualités, mais..."
Texte généré par ChatGPT Plus…mais qui permet aux modèles d’acquérir une compréhension très riche des significations des mots et de la géométrie de leurs relations
Si nous avons maintenant une idée assez précise de la façon dont procède ChatGPT pour construire les probabilités utilisées pour vous répondre, reste à savoir pourquoi ça fonctionne aussi bien.
Cette question nous ramène à une célèbre controverse concernant le test de Turing. Dans une expérience de pensée connue sous le nom de « chambre chinoise », le philosophe John Searle imagine en 1980 une personne enfermée dans une pièce avec un « manuel » contenant un ensemble de règles à suivre pour répondre à des questions formulées en chinois en manipulant des symboles, sans rien comprendre de cette langue. Un chinois qui dialoguerait avec cette personne sans la voir serait persuadée que son interlocuteur comprend le chinois – le test de Turing serait donc réussi –, alors même qu’elle se contente en réalité de suivre des instructions. Cette expérience pose implicitement la question de savoir si les outils tels que ChatGPT se contentent de construire des phrases sans en appréhender le sens.
De récents travaux conduits sur ces modèles permettent aujourd’hui d’apporter des éléments de réponse qui éclairent la façon dont ils fonctionnent.
Avant toute chose, il faut rappeler que chaque mot du vocabulaire de ChatGPT est associé à des coordonnées dans l’espace. Prenons un exemple très simple pour illustrer. Dans un espace à deux dimensions (x, y), le mot « roi » pourrait ainsi être représenté par les coordonnées (1, 2) tandis que le mot « reine » serait représenté par les coordonnées (2, 3). On peut facilement représenter cet espace graphiquement.

Comme on l’a vu, les coordonnées de chaque mot sont ajustées pendant l’entraînement du modèle en fonction de leur probabilité d’occurrence, de façon à ce que la distance entre deux mots reflète leur contexte d’utilisation dans le texte d’entraînement. Ainsi, des mots qui apparaissent souvent dans des contextes similaires (ex : roi et reine) seront placés plus près les uns des autres.
Derrière ce fonctionnement, il y a une vieille idée, qui trouve son origine dans les travaux liés à la sémantique distributionnelle : le sens d’un mot peut être déduit du contexte dans lequel il apparaît (« You shall know a word by the company it keeps », selon le mot célèbre de John Rupert Firth datant de… 1957). Ce qui change avec les grands modèles de langage, c’est que leur nombre très élevé de paramètres permet une représentation très riche du corpus d’entraînement. On est désormais bien loin de l’espace bidimensionnel présenté tout à l’heure : chaque mot est représenté dans un espace possédant un très grand nombre de dimensions et se voit donc associer plusieurs centaines ou milliers de coordonnées selon la taille du modèle.

De façon fascinante, les travaux conduits sur ces modèles tendent à confirmer le postulat de la sémantique distributionnelle : les coordonnées apprises pendant l’entraînement reflètent non seulement la syntaxe (la forme) mais aussi la sémantique (le sens) des mots.
Une étude récente a permis de l’illustrer graphiquement : elle montre qu’en traçant une droite entre deux mots formant les pôles opposés d’une dimension sémantique (ex : petit/gros, gentil/méchant, joyeux/triste) et en projetant sur cet axe les autres mots, on peut en déduire leur proximité dans cette dimension.
Par exemple, en traçant une droite entre « petit » et « gros » et en projetant sur cette droite les coordonnées de différents animaux comme dans l’exemple ci-dessus, le scorpion sera beaucoup plus proche de la souris que du requin. On peut placer les animaux sur une règle graduée allant de « petit » à « gros » pour en faciliter la lecture.

Si l’on procède de la même manière en traçant cette fois une droite entre « inoffensif » et « dangereux » pour refléter une autre relation sémantique, le scorpion se retrouvera cette fois plus proche du requin que de la souris.

L’intérêt de ce mode de représentation très riche est qu’il devient très facile de faire des rapprochements et des déductions.
Prenons l'exemple des pays et de leurs capitales. Si l’on capture la relation entre un pays et sa capitale, alors on peut ensuite très facilement déduire la capitale de n’importe quel pays. Il suffit par exemple de prendre le vecteur qui relie « France » à « Paris » et de l'ajouter à « Allemagne », ce qui permet bien d'obtenir la ville de « Berlin » (et non « Munich »).

Vous pouvez vous amuser à réaliser ce type d’opération sur les mots directement en ligne. Ainsi, l’opération « Allemagne + Paris – France » aboutit bien à « Berlin » et non « Munich ».

Ces dernières années, c’est justement en trouvant des manières de combiner beaucoup plus efficacement ces représentations des mots que les grands modèles de langage tels que ChatGPT ont pu faire des progrès considérables pour générer des réponses pertinentes.
En se fondant sur une nouvelle architecture inventée par des chercheurs de Google en 2017 et appelée « Transformer », ils parviennent à calculer à quel point chaque mot d’un texte est important par rapport aux autres mots qui le compose – et ce y compris pour des textes très longs. Grâce à la capacité de cette architecture à « faire attention » à l’ensemble du contexte de façon à obtenir une compréhension très fine de votre demande, les IA comme ChatGPT peuvent générer du texte de manière beaucoup plus cohérente et pertinente.
Vous comprenez maintenant comment, derrière un principe assez simple – « deviner le mot le plus probable » –, se cache un processus qui permet aux modèles d’acquérir et de mobiliser efficacement une représentation très riche des significations des mots et de la géométrie de leurs relations.
La « secret sauce » d’OpenAI
Reste à savoir ce qui a permis à l’entreprise OpenAI de se distinguer à ce point de ses concurrents avec la création de ChatGPT, qui demeure aujourd’hui de très loin le modèle jugé le plus efficace par les utilisateurs, dans sa version basée sur GPT-4.

S’il est difficile de répondre à cette question, dès lors que l’entreprise a cessé de diffuser ses modèles en open source, trois facteurs ont joué un rôle majeur.
Des modèles sous stéroïdes
Indéniablement, le « scaling » (« passage à l’échelle ») est le premier facteur explicatif de cette réussite.
OpenAI a fait plus tôt que ses concurrents le pari que les performances s’amélioreraient considérablement en augmentant radicalement la taille du modèle en termes de paramètres, de puissance de traitement et de volume de données d'entraînement. En passant de 1,5 milliard de paramètres avec GPT-2 (2019) à 175 milliards dans GPT-3 (2020), OpenAI se distingue clairement des autres modèles de langage disponibles à l’époque :

Quant à GPT-4, lancé début 2023, son nombre de paramètres n’est pas connu mais est estimé à 1,8 trillion par les analystes du secteur, soit l’équivalent d’un tableur excel grand comme 30 000 terrains de foot !

Si l’on se doutait qu’augmenter la taille des modèles leur permettrait de saisir des nuances plus fines du langage humain, on n’imaginait pas que cela les conduirait soudainement à afficher des performances remarquables en programmation informatique et en mathématiques ou de réussir des examens difficiles en droit et en médecine – bref, à en faire des outils à la fois très efficaces et extrêmement polyvalents.

Une formation complémentaire pour en faire un chatbot efficace et sûr
Au-delà du scaling, le succès d’OpenAI tient aussi à son choix de « renforcer » le modèle après sa phase initiale d’entraînement pour en faire un chatbot efficace et sûr.
En effet, le « modèle de base » entraîné à deviner quel mot devrait logiquement suivre le précédent dans une phrase permet uniquement de compléter un document. Face aux limites de cette approche, OpenAI a fait le choix décisif de lui faire subir une formation complémentaire pour apprendre au modèle à converser avec ses utilisateurs sous la forme de questions-réponses, afin de proposer une interface de dialogue intuitive et pratique à ses utilisateurs.
Concrètement, comment ça se passe ?
S’il comporte plusieurs étapes, cet entraînement fait notamment appel à l’avis d’humains en chair et en os, selon une approche développée par des chercheurs d’OpenAI et de Google en 2017. En pratique, plusieurs réponses alternatives générées par l’IA sont présentées à des « évaluateurs », qui doivent choisir celle qu’ils préfèrent. Les paramètres du modèle sont alors automatiquement ajustés pour tenir compte de ces préférences.
Si la méthode a fait polémique – le magazine Time ayant dénoncé le recours par OpenAI à des « travailleurs du clic » payés 2$ de l’heure au Kenya – , ce « renforcement humain » s’est révélé extrêmement efficace. Dès 2020, OpenAI annonce ainsi qu’un « petit » modèle de 1,3 milliard de paramètres entraîné à l’aide de cette méthode produit des réponses jugées plus pertinentes qu’un modèle de 12 milliards de paramètres n’ayant pas bénéficié de cet entraînement complémentaire.
Il peut être noté que pendant cette phase dite d’« alignement conversationnel », le modèle apprend non seulement à répondre de manière efficace mais aussi à respecter certaines règles et préférences externes – par exemple éviter de formuler des réponses jugées dangereuses. Ces règles sont généralement formulées en langage naturel (ex : « Si un utilisateur pose une question à caractère sexuel, ne réponds pas ») et constituent en quelque sorte des « super-consignes » (meta-prompts) que l’IA doit respecter avant de tenir compte des demandes particulières des utilisateurs.
C’est pour cette raison que vous aurez du mal à le faire disserter sur les moyens les plus efficaces de préparer un attentat ou les exploits de Staline.

Cet « alignement conversationnel » mis en place par OpenAI agit toutefois comme une forme de « filtre » dans la manière dont ChatGPT s’exprime, sans bouleverser les représentations du langage apprises par le modèle lors de son entraînement. En modifiant la façon dont la question est posée, des chercheurs ont ainsi montré qu’il est souvent assez facile de contourner ces limites.

En se risquant à une analogie avec la psychanalyse, on pourrait dire que l’« alignement conversationnel » mis en place par OpenAI pour modifier la manière dont ChatGPT s’exprime constitue une forme de « surmoi » visant à contraindre l’IA à « refouler » certains automatismes appris lors de son entraînement, qui demeurent néanmoins dans son « inconscient ».
Ce « retour du refoulé » très freudien a déjà été constaté pour d’autres types d’IA générative. Alors que le générateur d’images Midjourney a été « bridé » pour ne jamais créer des photos contenant des références sexuelles, l’artiste et chercheur Olivier Auber a ainsi découvert qu’en demandant à l’IA de créer « l’œuvre d’art la plus cachée de tous les temps », il obtenait des abstractions d’organes sexuels particulièrement explicites… avant de se faire bannir par l’entreprise américaine !
Au total, cette méthode permet ainsi d’obtenir, à partir du « modèle de base », un chatbot très efficace pour converser avec les humains et moins susceptible de produire des réponses jugées dangereuses pour la société.
Un fonctionnement multimodal
Après le scaling et le renforcement humain, reste un dernier facteur de succès des modèles d’OpenAI, plus récent dans sa mise en œuvre : la possibilité offerte à ChatGPT de s’appuyer sur des outils extérieurs pour élaborer sa réponse.
Là encore, OpenAI s’est appuyé sur des recherches récentes démontrant qu’il est assez facile d’apprendre à un modèle à solliciter de l’aide auprès d’un outil tiers en lui fournissant des indications générales sur leur utilité, assorties de quelques exemples. Il est assez fascinant de constater que ces consignes peuvent être exprimées en langage naturel à l’IA, comme si l’anglais ou le français devenait un langage de programmation.
Voici par exemple une illustration tirée du blog de Simon Willison, où ce dernier indique à une IA comment utiliser Wikipedia et un outil de calcul pour améliorer ses réponses :
You run in a loop of : “Thought” ; “Action” ; “PAUSE” ; “Observation”.
At the end of the loop you output an “Answer”.
Use “Thought” to describe your thoughts about the question you have been asked.
Use “Action” to run one of the actions available to you - then return “PAUSE”.
“Observation” will be the result of running those actions.
Your available actions are:
1/ calculate:
e.g. “calculate: 4 * 7 / 3” runs a calculation and returns the number using Python.
2/ wikipedia:
e.g. “wikipedia: France” returns a summary from searching Wikipedia.
Example session:
Question: What is the capital of France?
Thought: I should look up France on Wikipedia
Action: wikipedia: France
PAUSE
Observation: France is a country. The capital is Paris.
You then output:
Answer: The capital of France is Paris.Grâce à ce type d’apprentissage, le dernier modèle d’OpenIA est aujourd’hui capable de naviguer sur le web, d’utiliser un générateur d’images ou encore d’exécuter en local un code Python pour parvenir à répondre à votre demande. Un véritable game changer pour répondre à de nombreuses requêtes complexes, comme par exemple résoudre un problème de microéconomie.

Finalement, comme souvent en matière d’innovation, le succès de ChatGPT procède moins d’une percée technologique radicale d’OpenAI que de l’habileté remarquable de ses équipes à combiner diverses innovations récentes – souvent venues des laboratoires de recherche de Google ! – de manière créative et à les déployer à grande échelle pour offrir une expérience inédite aux utilisateurs.
Quelles leçons en tirer dans ses interactions avec les grands modèles de langage comme ChatGPT ?
Maintenant que vous connaissez les secrets de fabrication des grands modèles de langage (LLM), reste à en tirer les leçons dans vos interactions avec eux.
Pour ma part, j’en retiens principalement trois.
La première tient à l’importance de la rédaction de la consigne (le prompt). Changer légèrement le contexte fourni à l’IA peut aboutir à bouleverser les probabilités utilisées pour construire la réponse, car elle est dotée d’une représentation très subtile de notre langue.

La deuxième leçon tient au risque d’hallucination. Comme nous l’avons vu, ChatGPT se contente de construire une réponse probable, sans conception du vrai ou faux. Pire encore : il est conçu pour ne pas toujours choisir la réponse la plus probable, afin de proposer des réponses variées et créatives. De ce fait, il est donc susceptible de se tromper sur des questions factuelles pour lesquelles il ne dispose pas d’informations fiables et concordantes dans sa base d’entraînement. Ses erreurs sont d’autant plus difficiles à détecter qu’elles sont construites pour être statistiques probables – et donc plausibles.
Enfin, regarder « sous le capot » de ces grands modèles de langage permet de comprendre pourquoi ils sont susceptibles de produire des réponses biaisées. Les significations des mots et la géométrie de leurs relations ont été apprises par l’IA à partir des données d’entraînement qui lui ont été fournies. Si ces dernières sont « biaisées » idéologiquement, les réponses de l’IA le seront également. Pour prendre un exemple caricatural, une IA entraînée sur des textes affirmant que la terre est plate vous l’attestera sans sourciller dans ses réponses. Sans aller jusque-là, plusieurs études expérimentales ont démontré que les IA génératives tendent à reproduire les stéréotypes existants, tels que des préjugés de genre ou de race. Il est donc important de prendre du recul par rapport aux réponses fournies par l’IA et d’apprendre à interagir avec ces outils de manière critique. Nous y reviendrons !
Pour aller plus loin
Si vous souhaitez approfondir votre connaissance du fonctionnement de ChatGPT, je vous conseille vivement la lecture de l’ouvrage « ChatGPT décodé : comment fonctionne l'IA qui révolutionne notre monde ? » de Stephen Wolfram, désormais traduit en français.